サウンド系の深層学習に使うtorchaudio
この投稿はrioyokotalab Advent Calendar 2020 21日目の投稿です。
サウンド系の機械学習
PyTorchを使ってなにかするとなると、なぜか多くの人は画像をどうにかしようとしがちな気がします。特にブログとかでやってみた的な記事だとその傾向が強いと思います。確かにインパクトはありますし...。
画像処理はやり尽くされている感はありますが、音声系って意外とやられていない要素が多いように思います。もし、PyTorchで音声に関する機械学習を行いたいのであれば、この記事が参考になればと思います。
サウンド系機械学習のスタンダードな実装
音声というのは波情報です。それをそのまま1次元CNNにかけるというのでもいいのですが、波情報のままだと、情報が冗長すぎます。なので、基本的にはスペクトログラム1と呼ばれる、二次元情報に変換し、それを画像処理ベースのCNNにかけて特徴量抽出を行うというのが最近の主流です。
CNNから特徴量抽出を行う部分は画像処理と同様なので、特に実装に困ることは少ないと思いますが、波形情報を読み込んだり、波形情報をスペクトログラムに変換したり、スペクトログラムを正規化したりするのは簡単ではありません。特に、波形情報をスペクトログラムに変換するには離散高速フーリエ変換と呼ばれる技術が必要になり、それを自力で実装するのは困難です。GPU上で動かしたいとなったら、1ヶ月で作れるかどうかと言った話になってきます。これらの音声情報をよしなに処理してくれるライブラリがtorchaudioになります。
torchaudioの主要な機能
torchaudioを使うには
import torchaudio
をする必要があります。
音声ファイルの読み込み
音声データを扱うファイル形式は主にwavとmp3と呼ばれるものがあります。画像で例えるなら、PNGとJPEGといった感じのものになります。 これらのファイルから波形情報を読み込むには、
data, sampling_rate = torchaudio.load('./hoge.wav')
とする必要があります。波形情報は真にそのままのものを保持することは不可能なので、サンプリングレートと呼ばれる比率で1秒あたりサンプリングレート数分の点についての値を取ります。sampling_rateには、その比率が入っており、dataにはこのようにして離散的にサンプリングされた各時刻での値が入っています。なので、
plt.plot(data[0, sampling_rate//100*20:sampling_rate//100*21].numpy())
としてプロットすると
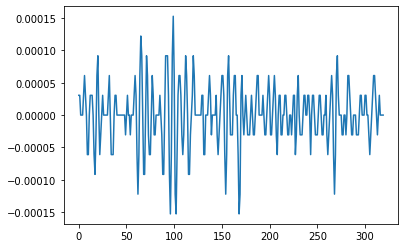 こんな感じに波形情報をとることができます。
こんな感じに波形情報をとることができます。
スペクトログラムの作成
spec = torchaudio.transforms.Spectrogram()
とすることで、波形をスペクトログラムに変換するモジュールを作成できます。
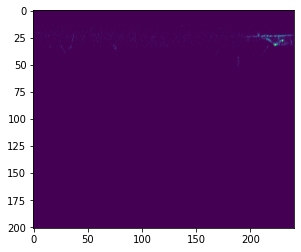
s = spec(data[:, sampling_rate*2:sampling_rate*3]) plt.imshow(s[0])
として実際にスペクトログラムに変換してみると
...
微かに何か見えていますが、よくわかりません。 実は、スペクトログラムに変換しただけだと、音圧という単位の値に変換されるだけなので、全体的に暗い画像になってしまいます。
デシベルに変換
音圧をdBという単位に変換します。音圧の対数を取るようです。スペクトログラムに変換するモジュールを作成したのと同様に、
amp = torchaudio.transforms.AmplitudeToDB()
としてから、
a = amp(s)
plt.imshow(a[0])
とすると、
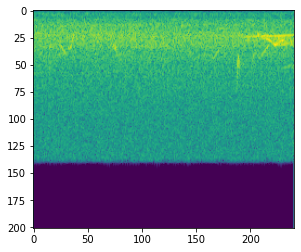
こんな感じの画像が生成されます。全体的にノイズが多い感じがしますが、所々特徴的な形状がみられます。これらを特徴を画像としてCNNにかけることで、特徴量抽出が行えます。
モデルへの組み込み
スペクトログラムの生成にはSpectrogramクラス以外に、MelSpectrogramという、より性能の良いクラスもあります。これらは、PyTorchのnn.Moduleとしてモデルに組み込むことができます。
例えば、
class SpectrogramEncoder(nn.Module): def __init__(self, args): super().__init__() self.melspcectrogram = MelSpectrogram(**args["params"]["melspectrogram_parameters"]) self.amplitude_to_db = AmplitudeToDB(top_db=80.) self.bn = nn.BatchNorm2d(3) def forward(self, x): x = self.melspcectrogram(x) x = self.amplitude_to_db(x) x = x[:, None].repeat(1, 3, 1, 1) x = self.bn(x) return x
という風に波形情報のエンコーダを作成することができます。さらに、これらのモジュールは他のPyTorchのモジュールと同じようにGPUに載せることができ、スペクトログラムの作成などをGPU上で行えるようにしてくれます。スペクトログラムへの変換を行ってくれるライブラリにはlibrosa2などもありますが、GPU上で行ってくれるという点や、他のCNNと組み合わせやすいという点でtorchaudioを使った方が良いと思います。
まとめ
音声情報で機械学習を行うための基本的なツールtorchaudioの紹介をしました。生成モデルやオートエンコーダー用の逆変換のモジュールもtorchaudioには含まれているので、必要に応じて使ってみると良いと思います。