競技プログラミングについて
この投稿はrioyokotalab Advent Calendar 2020 25日目の投稿です。
競技プログラミングとは
競技プログラミングとは、全年齢対象のオンラインゲームのジャンルの一つである。定期不定期期間問わず開催されるコンテストにて他の参加者と競い合いその最終結果をもとに、それぞれのプレイヤーのレート、メダルといった評価報酬がもらえるのがスタンダードである。
他のオンラインゲームとの大きな違いが、プレイヤースキルにおける比重が非常に重いことがあげられる。この特徴こそが多くの人をこのジャンルのゲームに引きつける要因とも言えるだろう。さらに、ガチャ、運要素もあり、コンテストの得意不得意や結果に多少の運要素が絡んでくることも、このゲームが人々を引き付けて離さない要因とも言える。しかし、運要素は大きなプレイヤースキルの差を潰すことはなく、圧倒的なプレイヤースキルの前には理不尽を感じ、逆に、圧倒的なプレイヤースキルで理不尽を叩きつけられることに公平性を感じ、その魅力を際立たせている。
課金要素は、競技プログラミングサイトごとによってまちまちであり、重課金によってある程度の成績が出せるようになるものから、課金要素がまったくないものまでまちまちである。しかし、ほぼすべてのサイトで課金するだけでトップクラスにいられるということはない。時に無課金が重課金を驚異的なプレイヤースキルで叩き潰すところが見れることもある。そういった、実力第一主義なところがこのゲームの魅力なのだろう。
そして、このゲームの最大の魅力は、ゲームのプレイを通して、その実力が現実のタスクに反映されうるというところにある。競技プログラミングで手に入れたプレイヤースキルは実社会においても使用可能なのである。自己の成長と娯楽を同時に達成しているところが、中毒性を増しているとも言える。
登録済み競技プログラミングサイト一覧
AtCoder
プレイヤースキル: ☆☆☆☆☆
必要プレイ時間: ☆☆☆★★
コミュニケーション能力: ☆★★★★
プロフィール
- 初段
- Rating 1860
- 青コーダー
(2020/12/25現在)
アルゴリズムコンテストをメインに開く日本最大手の競技プログラミングサイト。コンテストでは、コンテストによりますが、6問程度の問題が出題され、それぞれの問題では、現実の例に則した問題文と、入力と、その入力に求められる出力が示されます。私たちは、その入力と出力を達成するアルゴリズムを考案し、プログラムし、そのプログラムを提出することが求められます。プログラムには実行時間制限が設けられており、たとえ正しいプログラムであったとしても、非効率なアルゴリズムを実装した場合、不正解とされます。提出したプログラムは10から100件程度のテスト入力によって正しい出力が生成されているかをチェックされ、そのすべてのテストデータに正解することで、そのコンテストにおけるその問題の得点を獲得することができます。 最終結果は、正解した問題の得点の合計で競われ、得点が同じ場合は最後の問題を提出した時刻の速さで競われます。
AtCoderで勝つためには、大量の情報数学とプログラミングの基礎知識を身に着ける必要があります。このことから、AtCoderでの強さはプログラマーとしての強さそのものではないですが、ありとあらゆる方面のプログラマーになるための下地になります。じっくり時間をかけてIT系の道を目指すのであれば、最も上に進むための入り口になり得ますが、ここで身につけた実力が成果に反映されるようになるには、想像以上に時間がかかるかもしれません。
シンプルな実力のみでのぶつかり合いを楽しみたい人におすすめのゲームサイトです。
ICPC 国際大学対抗プログラミングコンテスト
プレイヤースキル: ☆☆☆☆☆
必要プレイ時間: ☆☆★★★
コミュニケーション能力: ☆☆☆★★
- 2019年にunlimited greedyのメンバーとして参加
- 国内予選 18位 突破
- アジア予選 38位 敗退
国際大学対抗プログラミングコンテストと呼ばれるこのコンテストは大学内で3人1組のチームを組み参加するコンテストです。AtCoderと同じような形式の問題が10問程度出されます。正解の決め方もAtCoderと同様です。ただし、順位の決め方は、得点順で決めた後、同点のチームについては、解けた問題それぞれの提出時間の合計となっています。
このコンテストサイトの面白いのは、国内予選、地域予選の2つの予選を勝ち抜き、世界大会で優勝者を決めるということです。予選や世界大会は年に1度しか開催されず、大学の一つの青春をそこに捧げます。
チームを組むことで、思考の共有や議論が生まれ、大学の間に身につけてきた実力をさらにひとまわり成長させてくれることでしょう。
Kaggle: Your Machine Learning and Data Science Community
Kaggle
プレイヤースキル: ☆☆☆☆★
必要プレイ時間: ☆☆☆☆☆
コミュニケーション能力: ☆☆☆☆★
プロフィール
- Kaggle Master
- 最高ランク 26位
- 現ランク 78位
(2020/12/25現在)
機械学習系のコンテストをメインに扱うコンテストサイトです。一回のコンテストの期間は、コンテストによりますが、おおよそ3ヶ月程度で、その期間で与えられたデータセットに対する機械学習モデルの設計を行います。機械学習モデルの性能を上げるためには、実験の積み重ねによるデータの知見の蓄積が必要になってきます。そのため、アルゴリズム系のコンテストサイトに比べて、一度のコンテストにかける時間が比較的多いように感じます。また、チームを組むことも可能で、チーム内でデータの知見の共有を行うことで、より良い機械学習モデルの作成を可能にします。そのため、プレイヤースキル以外にも、高いコミュニケーション能力を必要とします。また、開催中のコンテストについて情報をチーム外に共有することが禁止されているため、機械学習についての様々な知見を得て成長するためには積極的にチームを組んでコンテストに参加する方が望ましいです。
順位はPublicとPrivateという二種類があり、それぞれ、Public Test DataとPrivate Test Dataに基づいて提出された機械学習モデルの推論プログラムによる性能が評価されます。Publicはコンテストが開催中であっても見ることが可能で、自分のモデルが他チームと比較してどの程度いい性能を出しているかを図る目安になります。Privateはコンテストの真のスコアで計算される順位で、コンテストの最終成績はPrivateの順位で決定されます。PublicとPrivateの順位の入れ替わりはコンテスト毎に話題になる程多くの人が気に掛ける要素となっています。
機械学習という最先端な技術を扱っているゲームサイトなので、コンテスト毎に面白い発見がなされ、共有されます。自分の持っている知識で、新しい境地を開拓したいという人におすすめのゲームサイトです。
まとめ
競技プログラミングは人生
交差検証の使い道
この投稿はrioyokotalab Advent Calendar 2020 24日目の投稿です。
交差検証法
機械学習をやる上で、検証は最重要の技術だと言えます。検証を行うにあたって、よくあるのが、データセットの一部をテストデータとして検証に回すというのがありますが、もしかして、そのテストデータでチューニングしたスコアが論文に掲載されてたりしてないですよね...。
適切な機械学習を行うためには、テストデータにたいしてチューニングするのはタブーとされています。なぜなら、テストデータに対してチューニングを行うと、テストデータが保有している統計的な情報を含めてチューニングしてしまう可能性があるからです。
テストデータはあくまで、最終的な性能評価の一発勝負のスコアの計算に用いられるべきで、検証用のデータセットは別にデータを分けてearly stoppingなどを行う必要があります。しかし、データセットを減らして学習すると性能が劣化してしまいます。そういう問題に対処できる検証法が交差検証法なのです。
交差検証法とは
交差検証法とは、学習データを5つとかに分割して(分割の仕方もまた重要)それぞれを検証データ、それ以外を学習データとした複数のモデルを学習させる方法です。
まず、データセットを分割します。分割したデータをそれぞれ検証用として、検証用に含まれなかった分割分を学習用として、検証・学習データのペアを作ります。それぞれfold0からfold4と呼びます。

それぞれのfoldで検証を行いながら、学習を行ったら、今度は推論データを作成します。モデルにはそれぞれのモデルの学習時に検証用として用いたデータを入力とし推論を行います。

こうすることで、学習データ(ラベルがついている)全てに対して検証用の推論結果を入手することができます。この推論データと学習データのラベルを組み合わせることで、学習データ全体に対して、検証スコアを計算することができます。
テストデータに対して推論を行う場合は、このどれか一つのモデルを使用するか、すべてのモデルで推論を行い、モデルアンサンブルとしてその平均を推論として出力します。

検証の戦略が間違っている場合、テストデータの検証スコアと、学習データ全体に対する検証スコアの間に差が生じます。この差が生まれないことを確認するためにテストデータでのスコアの計算は行われます。
この一連の検証方式の流れが交差検証法(Cross Validation:CV)と呼ばれる物です。正しい検証が行えるようになると、検証データでチューニングした結果が実運用環境に反映されやすくなります。それは、機械学習の社会適用において重要なことなのです。
交差検証法の使い道その1 スタッキング
スタッキングというのは機械学習の性能がなぜか上がる、アンサンブル手法の一種です。簡単に言えば、モデルの出力結果を入力とした新しい機械学習モデルを追加することを言います。特に複数のモデルの出力をまとめて新しい機械学習モデルの入力とすることが多いです。
この時、新しいモデルはテストデータの出力結果を入力として想定しなければなりません。学習データの出力結果は、教師ラベルに強くフィッティングしているので、そのまま新しいモデルに入力すると、過学習を引き起こしてしまいます。(火を見るより明らか)
学習データを入力とした時のテストデータの出力と似た出力はどのようにして手に入れたら良いでしょうか。そう、交差検証法で作った検証データの推論を使えば良いのです。
スタッキングという手法については、検索をかけるとたくさん記事があるのでそちらを参考にしてください。
交差検証法の使い道その2 データクリーニング
学習データというのは必ずしも完璧にラベル付されているわけでも、適切な画像になっているわけでもありません。そのようなデータセットを用いて学習を行うと用意に過学習を引き起こします。そのような事態を回避するためにはデータセットの中身をきれいにする必要があります。
しかし、ラベルが正しいかどうかはどのように判断したら良いでしょうか。人手ですべて目視で確認することもできますが、ラベル付に専門的な知識が必要な場合はどうでしょう。ラベルの正確性の検証には様々な方法がありますが、一旦、推論の結果と合うかどうかとか、推論の確信度が高いかどうかなどを確認してみるのが手っ取り早い方策だと思います。
その場合、学習データ全てに対しての推論結果が必要になります。それは、交差検証法によって手に入ります。
まとめ
学習データから予期される出力がすべて見れるだけで、データ分析の道筋は大きく広がります。それを可能にする交差検証法、やっといて損なことは絶対にないので、機械学習をやるのであれば、徹底して行いましょう。
個人的 Neural おもしろ Network
この投稿はrioyokotalab Advent Calendar 2020 23日目の投稿です。
勾配法の発展
深層学習は最近では主に画像分類の分野において今までの機械学習では達成できなかったような精度を出せるようになっています。それを達成したのは勾配法というただ一つのアルゴリズムでどんな構造のモデルであっても学習してしまおうというシンプルなアイデアであると言えます。こうすることで、クラス分類であればクロスエントロピーを、回帰であれば、最小二乗法を用いてその背後に適当なニューラルネットを置くことで幅広いチューニング性と拡張性を獲得しました。そして、それを利用して、最近では、セグメンテーションタスクや物体検出タスクのような、本来であれば、損失から勾配が取りづらいようなタスクに対しても様々な工夫を凝らして勾配を取り、勾配法による学習を可能にしています。
勾配法による機械学習の流行によって、勾配が取れる構造はたくさん開発されてきました。それらを組み込んだモデルは従来の機械学習では想像されてこなかったインパクトのある成果を産み出してきました。今回はその中から個人的に面白いと思うネットワークTop3を紹介していきたいと思います。
第3位 Spatial Transformer Networks
paper: https://arxiv.org/abs/1506.02025
画像の配置方法の勾配を取れるようにした構造です。

画像の変換をグリッド状のサンプリングによって行うことで、各ピクセルが求めている変換方向を勾配として取ることができるようになっています。これをまとめてAffine変換のパラメータなどに逆伝播させることで、Affine変換の学習などが行えます。
STNは勾配のみで画像の切り抜き位置を探すことができるので、弱教師あり主体オブジェクト位置検出や、背景の切り取りなどが行えます。また、通常のネットワークの前にSTNを含むCNNを配置することで、ネットワークが見る位置を限定するとともに、判断根拠を示すことができたりもします。

第2位 Generative Adversarial Networks
paper: https://arxiv.org/abs/1406.2661
高品質な生成モデルを学習するアルゴリズムです。 画像を生成するGeneratorと生成データか実データかを見分けるDiscriminatorという二つのニューラルネットをGeneratorはDiscriminatorを騙せるように、DiscriminatorはGeneratorの生成した画像を見分けられるように、敵対的に学習することで、画像データを用意するだけで、それっぽい画像の生成を可能にした驚きのアルゴリズムです。

ヤン・ルカンは、GANsについて、「機械学習においてこの10年間で最も興味深いアイデア」("This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.")と評価している[2]。
今も活発に研究されていて、生成モデルに限らず、この敵対的損失を利用した様々な応用手法も開発されています。例えば、Bengali.Ai Handwritten Grapheme Classificationというコンペティションで1stを取った手法では、半教師あり学習の一部に敵対的損失を用いた構造が含まれています。
第1位 Connectionist Temporal Classification Loss
paper: https://www.cs.toronto.edu/~graves/icml_2006.pdf
通称CTC Lossと呼ばれています。CTC Lossは時間均一な系列情報を離散的な単語的系列情報にクラス分類してくれるという優れものです。具体的なタスクを示すなら、音声の文字起こしというタスクに使われる物です。例えば、音声の波形情報からCNNで特徴量抽出を行って、その発音を50音に直すようなタスクの学習が行えます。この時、50音のそれぞれの発音時間はまばらなので、特徴量マップにもそのまばらさが現れてしまいます。それを良い感じにまとめてくれるという機能が追加されていてしかも勾配が取れるというびっくりアルゴリズムなのです。
下図は論文から引用した物ですが、CATの3文字をどの時刻から持ってくることが可能かというパスの総パターンを表現しています。白い点はblankと呼ばれるクラスで、空欄であるということを示しています。このパスによって、時刻ごとのクラスへの様々な割り当て方を考えることができます。

例えば、次のような割り当て方が考えられます。

それぞれの割り当て方の確率は特徴マップがそのクラスに割り当てられる確率を系列全体で総積を取ることで計算できます。
そして、損失関数としては、
CATという系列に割り当てられる確率が欲しいので、すべての割り当て方の確率の総和を取れば良いことになります。
この確率を最大化するように学習すれば良いという話なのですが、すべての割り当て方を網羅するのは現実的ではありません。それを動的計画法を含む天才的なアルゴリズムで可能にしたのがCTC Lossなのです。
応用先は、音素解析、光学文字列認識などがあります。
まとめ
今回は、勾配法で学習するモデルに組み込める勾配を扱える面白いネットワークの紹介をしました。自分でただタスクに取り組んでいるだけでは絶対に思いつけないようなユニークなモデル構造を発明した先人には頭が上がりません。
こういうユニークなモデルを駆使して、なんか面白い物を作ってみたい物ですね。
サウンド系の深層学習に使うtorchaudio
この投稿はrioyokotalab Advent Calendar 2020 21日目の投稿です。
サウンド系の機械学習
PyTorchを使ってなにかするとなると、なぜか多くの人は画像をどうにかしようとしがちな気がします。特にブログとかでやってみた的な記事だとその傾向が強いと思います。確かにインパクトはありますし...。
画像処理はやり尽くされている感はありますが、音声系って意外とやられていない要素が多いように思います。もし、PyTorchで音声に関する機械学習を行いたいのであれば、この記事が参考になればと思います。
サウンド系機械学習のスタンダードな実装
音声というのは波情報です。それをそのまま1次元CNNにかけるというのでもいいのですが、波情報のままだと、情報が冗長すぎます。なので、基本的にはスペクトログラム1と呼ばれる、二次元情報に変換し、それを画像処理ベースのCNNにかけて特徴量抽出を行うというのが最近の主流です。
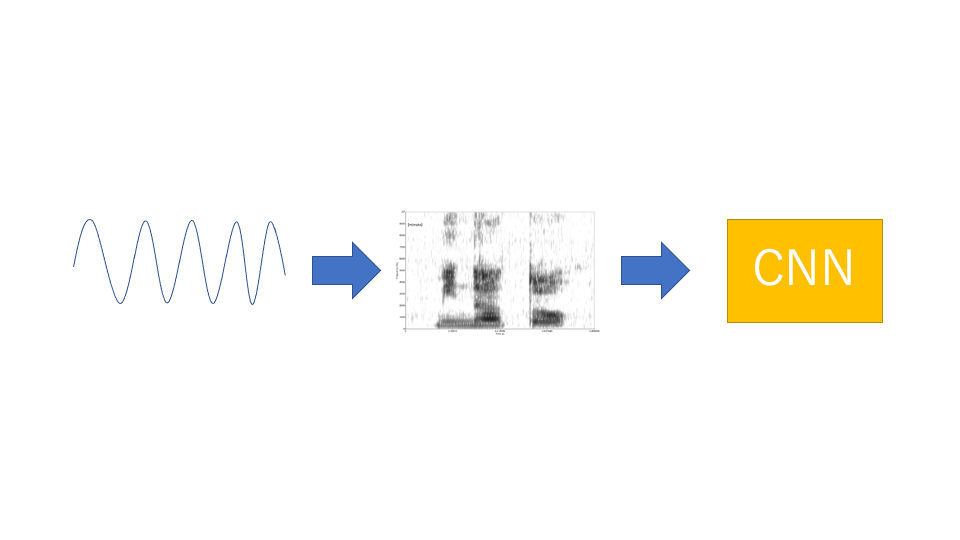
CNNから特徴量抽出を行う部分は画像処理と同様なので、特に実装に困ることは少ないと思いますが、波形情報を読み込んだり、波形情報をスペクトログラムに変換したり、スペクトログラムを正規化したりするのは簡単ではありません。特に、波形情報をスペクトログラムに変換するには離散高速フーリエ変換と呼ばれる技術が必要になり、それを自力で実装するのは困難です。GPU上で動かしたいとなったら、1ヶ月で作れるかどうかと言った話になってきます。これらの音声情報をよしなに処理してくれるライブラリがtorchaudioになります。
torchaudioの主要な機能
torchaudioを使うには
import torchaudio
をする必要があります。
音声ファイルの読み込み
音声データを扱うファイル形式は主にwavとmp3と呼ばれるものがあります。画像で例えるなら、PNGとJPEGといった感じのものになります。 これらのファイルから波形情報を読み込むには、
data, sampling_rate = torchaudio.load('./hoge.wav')
とする必要があります。波形情報は真にそのままのものを保持することは不可能なので、サンプリングレートと呼ばれる比率で1秒あたりサンプリングレート数分の点についての値を取ります。sampling_rateには、その比率が入っており、dataにはこのようにして離散的にサンプリングされた各時刻での値が入っています。なので、
plt.plot(data[0, sampling_rate//100*20:sampling_rate//100*21].numpy())
としてプロットすると
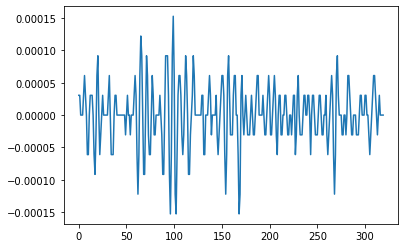 こんな感じに波形情報をとることができます。
こんな感じに波形情報をとることができます。
スペクトログラムの作成
spec = torchaudio.transforms.Spectrogram()
とすることで、波形をスペクトログラムに変換するモジュールを作成できます。
s = spec(data[:, sampling_rate*2:sampling_rate*3]) plt.imshow(s[0])
として実際にスペクトログラムに変換してみると
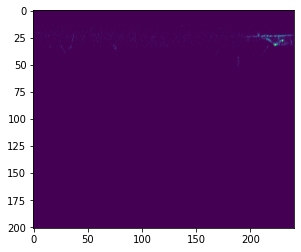
...
微かに何か見えていますが、よくわかりません。 実は、スペクトログラムに変換しただけだと、音圧という単位の値に変換されるだけなので、全体的に暗い画像になってしまいます。
デシベルに変換
音圧をdBという単位に変換します。音圧の対数を取るようです。スペクトログラムに変換するモジュールを作成したのと同様に、
amp = torchaudio.transforms.AmplitudeToDB()
としてから、
a = amp(s)
plt.imshow(a[0])
とすると、
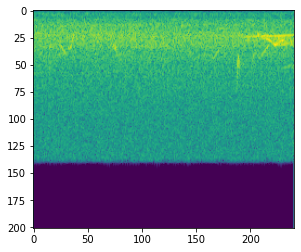
こんな感じの画像が生成されます。全体的にノイズが多い感じがしますが、所々特徴的な形状がみられます。これらを特徴を画像としてCNNにかけることで、特徴量抽出が行えます。
モデルへの組み込み
スペクトログラムの生成にはSpectrogramクラス以外に、MelSpectrogramという、より性能の良いクラスもあります。これらは、PyTorchのnn.Moduleとしてモデルに組み込むことができます。
例えば、
class SpectrogramEncoder(nn.Module): def __init__(self, args): super().__init__() self.melspcectrogram = MelSpectrogram(**args["params"]["melspectrogram_parameters"]) self.amplitude_to_db = AmplitudeToDB(top_db=80.) self.bn = nn.BatchNorm2d(3) def forward(self, x): x = self.melspcectrogram(x) x = self.amplitude_to_db(x) x = x[:, None].repeat(1, 3, 1, 1) x = self.bn(x) return x
という風に波形情報のエンコーダを作成することができます。さらに、これらのモジュールは他のPyTorchのモジュールと同じようにGPUに載せることができ、スペクトログラムの作成などをGPU上で行えるようにしてくれます。スペクトログラムへの変換を行ってくれるライブラリにはlibrosa2などもありますが、GPU上で行ってくれるという点や、他のCNNと組み合わせやすいという点でtorchaudioを使った方が良いと思います。
まとめ
音声情報で機械学習を行うための基本的なツールtorchaudioの紹介をしました。生成モデルやオートエンコーダー用の逆変換のモジュールもtorchaudioには含まれているので、必要に応じて使ってみると良いと思います。
pytorchのnon_blockingという機能が使えると思った
この投稿はrioyokotalab Advent Calendar 2020 19日目の投稿です。
デバイス転送部分がボトルネックになる可能性
PyTorchのCUDAで動作する部分は非同期で動いてくれるらしいです。[要出典]なので、特に何も意識しなくても、データの読み出しとかにかかるCPUの計算時間をモデルのforward, backwardの計算時間に隠してくれるようにできています。つまり、CPU側の作業とGPU側の作業を並行して行ってくれるということです。
この時、データをCPUメモリからGPUメモリに移動する作業が時間がかかる場合があります。そこを、非同期にするオプションがあるらしいです。
CPUメモリ上のtensorをGPUメモリに移すためには、toメソッドを呼びます。このtoメソッドの引数にnon_blockingという引数があり、これにTrueを渡すことで、非同期に転送ができるらしいです。
non_blockingについての議論されているのはこちら discuss.pytorch.org
non_blockingで速度が上がったという報告はこちら qiita.com
実験
ひなどりクラスタ上で試してみました。確保したノードはtitanvです
とりあえず、
- 画像サイズ512x512
- バッチサイズ 64
- モデル ResNet18
- DataLoader num_worker=1, pin_memory=True
で試してみました。
non_blocking=True
non_blocking=False

うーん... 別段早くはならない...
まとめ
いかがでしたか?non_blockingについて試してみましたが別段早くはなりませんでした。
載せた実験以外にもいくつか試してみましたが、明確に早くなったものはありませんでした。
必要な条件がわかったら追記しようと思います。
ゼロ割が見つからない時のNaNの原因
この投稿はrioyokotalab Advent Calendar 2020 17日目の投稿です。
深層学習中最悪のバグ
深層学習の学習コードを何度も自前で組んでいるといつか出くわすNaN。時に再現性が無かったり、再現するのに1時間かかったり、ひたすらにプログラマの頭を悩ませることになります。もちろん、PyTorchのデバッグ機能をしっかり利用して見つけられることもありますが、学習が進むにつれて、とある値がアンダーフローやオーバーフローすることによって、発生するNaNは原因を特定するのがひたすらに面倒です。しかも、精度を大きく改善させられそうなユニークなアルゴリズムを実装した時に限ってそういうNaNはよく発生するものです。そして、このNaNを解決するためには、時にエスパーと呼ばれる、プログラマの特殊能力が必要になります。
NaNに対処するための記事はググればいくらでも出てきます。今回は、ゼロ割じゃないと言い切れる場合に起きうるもう一つのよくありがちなNaNの可能性を紹介します。
見つからないときはbackwardを想像する
自分がNaNに悩まされた時に一番役立った記事がこちら
forwardの計算式はプログラム上で明示的に書かれているので、ゼロ割や以上に巨大な値を出していないか探すのにそこまで苦労はしないと思います。しかし、backwardは結構忘れがちです。まさに自動微分フレームワークという甘ったれた機械学習環境に頼り切ったでーたさいえんてぃすとの自業自得ってやつですね...。
具体的に
sqrt
ベクトルのノルム などを計算する時によく出てくるsqrtです。ベクトルを正規化する時に
などとして、ゼロ割を回避してやった気でいると、踏んでしまうやつです。ちなみにPyTorchのWeightNormalizationというクラスは、ここのゼロ割対策が入っておらず、自前で実装し直す必要がありました。その時に私が踏みました。
正しくは、
としてやる必要があります。
sqrtは中身が0の時、勾配がinfに飛ぶので、中身が0にならないようにしなければなりません。

まあ、確かに勾配が真上を向いている気がする...
おまけで
atan2
の二次元ベクトルの原点と、
から見た角度を出力する関数です。metric learningとか、空間認識系のタスクに必要なのでしょうか。使ったことがないのでわかりません。
を入れると、計算途中で、
が計算されるため、
が計算されるため、値が
NaNになります。

まあ、何が計算されているのかわからないですね。
まとめ
深層学習の自動微分コードはbackwardまでが実装コードであることを意識しておくこと。さもないと、丸一日分の進捗が無に帰すことになります。
CSVが遅かったらfeather形式で読み込もう
この投稿はrioyokotalab Advent Calendar 2020 15日目の投稿です。
とりあえずCSV
機械学習においてデータというのは、切っても切れない関係にあります。データを管理する形式はいくつかあります。画像データであれば、
- ラベル情報をファイル名にして画像ファイルを保存
- テキストデータにファイルパスとラベルをセットにしてスペース区切りで保存
- テーブルデータ(pandas1のデータフレーム)形式で、ファイルパスとラベル、インデックスなどを保存(例えば、CSV)
などなど...
Kaggleでは、データに対して、交差検証用のfold_idや、データの性質をハンドラベリングしたりなど、データに新たな情報を加えることが多かったり、データやラベルの統計情報、傾向などを把握するために操作するため、pandasのデータフレーム形式で持てるようにするのが一般的です。そのため、シンプルなCSVを使ってデータの管理をすることが多いのですが、生データでの可読性がある代わりに、csvは文字データでデータを保存しているためか、データ量が多くなると洒落にならないくらい遅くなります。
この記事では、CSV以外にもpandasのデータフレームとしての取り回しやすさを保持したまま、高速にIOが行えるデータ形式であるfeather2の紹介をします。
feathreフォーマット
中身はよくわかっていません。headコマンドで覗いてみたら、ヘッダー情報をjson形式のようなもので保持していて、その後、よくわからないバイナリ情報がだらだらと続いていました。
pyarrowってやつで読めるものらしいのですが、要は、pandasで読めるなんかしらのデータ形式です。
速度比較
pandasで読み込めるテーブルデータの保存形式の速度比較には、次の記事が参考になります。
これを見ると多少の得意不得意はあるものの、全体的に安定して、feathre形式が高速なIOを行えていることがわかります。
手元の実験環境での検証
最近の実験で使っていた Bengali.AI Handwritten Grapheme Classification | Kaggleのデータセットを加工した物を使って実験を行います。
今回、実験に使うのは、137 x 236ピクセル,uint8のベンガル語の画像データを1次元データに並び替えて格納した、200840件のテーブルデータセットです。マシンスペックはABCI3の計算ノード1つ(80スレッド)で試します。
この200840件の画像データの読み出しにかかる時間を計測します。
実験1 CSV形式
15分以上はかけましたが、終わりませんでした。
終わりました。

dtypeとかを指定すればもっと早くなったかも。
実験2 feathre形式

feathre形式はマルチスレッドも入れてくれるようなので、だいぶ早いです。これくらいの時間ならストレスフリーに実験を回せます。
実験3 pngで保存して読み出し
試しに一つの画像を保存して、その画像を200840回読み出してみます。

こちらもシングルスレッドで回しているにしてはだいぶ早いです。画像の大部分が白く、情報が少ないため、pngの圧縮がうまくはたらいて早く読み出せたのかもしれません。
まとめ
pandasにはfeathre形式を読み込むためのread_feathreメソッドとfeathre形式に書き込むためのto_feathreメソッドがあります。データの読み出し速度に悩んだ場合は、検討してみるといいと思います。特に、すべてのデータをとりあえずメモリ上に乗っけてしまいたいという場合には、いい選択肢になると思います。
他にもpandasが扱えるデータには、parquetと呼ばれるデータ形式やhdf5というデータ形式もあります。それぞれのデータ形式には、そのデータ形式がある理由になる得意な状況というのが存在するので、それらにも目を通して、必要に応じて様々なデータ形式を使い分けられるようになりたいですね。